EMMApro – Erweiterte Methoden des Maschinellen Lernens für die Prozessindustrie
Felix Gandha Salentin, Leitung: Prof. Dr. Dierk Hartmann
EIDOminer ist eine von der Hochschule Kempten und der Universität Duisburg-Essen entwickelte Softwareumgebung, die unterschiedliche Methoden des maschinellen Lernens implementiert und sich auf Fertigungsprozesse spezialisiert. Prognosefunktionen lassen sich trainieren und anhand eines sogenannten Supervisors für technische Prozesse optimieren. Das Grundprinzip der Software besteht darin, die Arbeit mit maschinellem Lernen in Fertigungsumgebungen zu vereinfachen und ihren Nutzen Anwendern ohne tiefes Hintergrundwissen zugänglich zu machen. Die Software besteht im Wesentlichen aus drei Kernkomponenten: Explorative Datenanalyse, Datenvorverarbeitung, Modelltraining und -evaluation. Als Datenquellen werden Excel und CSV-Dateien, Daten aus URLs und Datenbanksystems wie MySQL, Microsoft SQL-Server und Microsoft Access unterstützt.
Für jede Prozessvariable lassen sich relevante Statistiken anzeigen. Die deskriptive Datenanalyse umfasst folgende Funktionen:
- wesentliche Merkmale wie Ausreißer und fehlende Werte
- Informationen zur Verteilung wie obere und untere Quantile sowie Interquartilsbereich
- deskriptive Statistiken wie Median der absoluten Abweichung, Variationskoeffizient, Wölbung, Schiefe, Prozessfähigkeitsindex (Cpk)
- Häufigkeitsverteilungen und Histogramme
- Hervorhebung von Korrelationen hochkorrelierter Variablen, Spearman-, Pearson- und Kendall-Matrizen
Die Datenvorverarbeitung ist ein fester Bestandteil des Workflows. Den Nutzenden werden konkrete Handlungsvorschläge zur Verbesserung der Datenqualität gemacht. Bei tabellarisch strukturierten Daten umfasst die Datenverarbeitung des EIDOminersfolgende Module:
- Datenbereinigung: Entfernen oder Korrigieren von Datenzeilen mit fehlerhaften Werten und Ausreißern sowie Datenzeilen mit einer Vielzahl von fehlenden Einträgen.
- Merkmalsextraktion: Reduktion der Zahl funktional unabhängiger Variablen für eine verbesserte Modellperformance und weniger Redundanz. Die verwendeten Verfahren sind unter anderem PCA, SVD und KPCA.
- Abstimmung von Merkmalen: Normalisierung numerischer Werte bei stark heterogen skalierenden Variablen, Imputation fehlender Werte und Anpassung von Werten mit asymmetrischer Verteilung
Nach der Datenvorverarbeitung können Modelle des maschinellen Lernens trainiert werden. Für Regressionsprobleme werden 26 Algorithmen mit umfangreichen Parametereinstellungen implementiert, während 23 Algorithmen für Klassifikationsprobleme umgesetzt werden. Darunter befinden sich verbreitete Verfahren wie Neuronale Netze, Support Vector Machines, Entscheidungsbäume und Weitere. Es stehen weiterhin Ensembleverfahren mit der Bezeichnung Supervisor sowohl für Regressions- als auch für Klassifikationsaufgaben zur Verfügung.
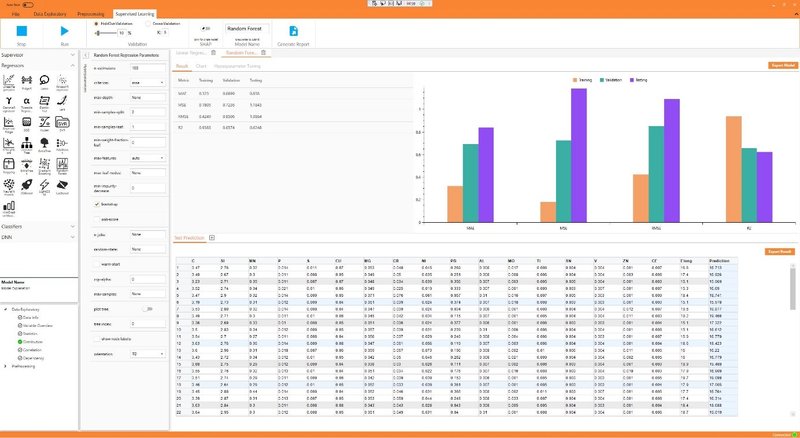
Die Trainingsergebnisse werden je nach Aufgabe anhand verschiedener Metriken dokumentiert. In einem konkreten Anwendungsfall soll die Bruchdehnung eines Gussteils anhand seiner chemischen Komponenten vorhergesagt werden. Die Nutzenden sind in der Lage, Hyperparameter einzustellen und das Modell des maschinellen Lernens auszuwählen, das das beste Ergebnis liefert. Um das Trainingsergebnis zu bewerten, bietet der EIDOminerverschiedene Visualisierungstools. Regressionen können in Form von Residuen oder als Streudiagramme dargestellt werden. Klassifikationen lassen sich mit einer Konfusionsmatrix visualisieren. Die Diagramme können für Projektdokumentationen genutzt werden und dienen der Kommunikation von Analyseergebnissen.
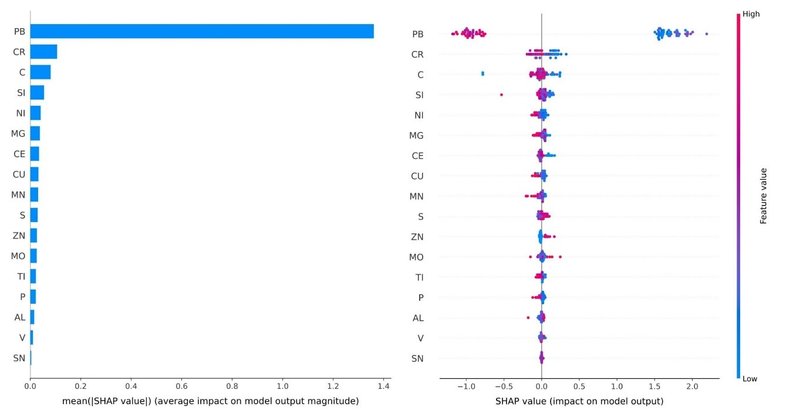
Der Interpretierbarkeit von maschinellem Lernen wird eine immer höhere Bedeutung beigemessen. In Praxisanwendungen ist Transparenz bei datengetriebene Modelle gefordert. Für die empirische Modellinterpretation werden hier zwei Methoden genutzt: Featurerelevanz und SHAP-Werte. Sie können herangezogen werden, um die treibenden Einflussgrößen eines Prozesses ausfindig zu machen und Wirkzusammenhänge offenzulegen.
Für die Lernverfahren ist eine intelligente Anpassung der Hyperparameter implementiert. Letztere werden zunächst auf Grundlage von Erfahrungswerten vordefiniert. Die Nutzenden können zur Optimierung der Trainingsergebnisse eine automatische Parametersuche initiieren.
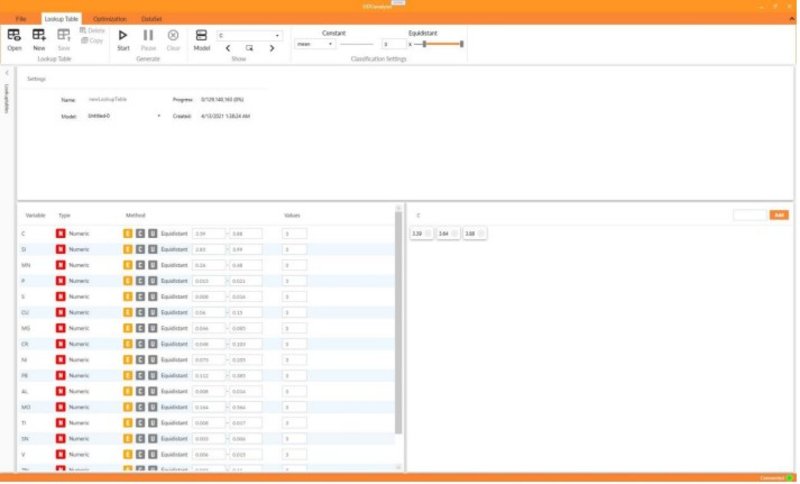
EIDOAnalyser ist eine weitere Teilkomponente der Software. Sie ermöglicht die Optimierung von Fertigungsprozessen hinsichtlich ihrer Qualitätsmerkmale. Trainierte Modelle werden genutzt, um eine Lookup-Tabelle zu erstellen. Sie beinhaltet alle umsetzbaren Parametervariationen und kann im laufenden Prozess abgerufen werden, um eine Einstellung zu finden, so dass der Prozess die geforderten Qualitätsmerkmale erfüllen.